オンライン不正利用防止に機械学習が有効な理由とは?
-
 │
│
GoogleのAlpha Goが初めて人間のプロ棋士に勝利をおさめ、大きな話題となったのは2016年のことでした。コンピューティング・パワーの向上やビッグデータの大規模な利用など、テクノロジーの進歩により、ビジネスにおいてもさまざまな分野で機械学習が導入され始めています。ウェブサイトにおける不正利用防止は、最も機械学習が適したアプリケーションの1つです。
なぜ不正利用防止に機械学習技術が役立つのか
昨今の大規模なデータ漏洩事件により、ダークウェブにはアカウントの乗っ取りや個人情報の窃盗に利用可能な財務情報や個人情報が溢れています。また、悪質な業者は、ユーザ生成コンテンツを不正に利用し、詐欺やスパムの投稿などを行っています。
サイバー犯罪者の技術はますます高度化しています(前回の記事)。犯行に必要な機材やツールは非常に低コストで入手することが可能です。 オンラインでビジネスを行う企業にとって、彼らは最新の技術を用いて攻撃方法を頻繁に変えるやっかいな相手です。機械学習は、サイバー犯罪者からの攻撃に先手を打つために大いに役立ちます。
機械学習が有用な理由は3つあります。まず一つ目の理由は、大量のデータを扱えることです。不正利用を検知する最も効果的な方法は、エンドユーザの幅広い行動を調べることです。ログインや注文のみならず、そこに至るまでのすべてのクリックや画面遷移、注文完了後のふるまいまで含めた膨大な項目が含まれます。このようなデータから不正利用を判別するためのツールとして、機械学習は最も適していると言われています。
二つ目の理由は、変化に素早く自動で対応できることです。不正利用を行うサイバー犯罪者は常に手口を変えてくるため、人間が検知するのは非常に難しく、学習しない静的なルールベースのシステムでは検知することが困難です。しかし機械学習モデルは、最新のデータを用いて変化するサイバー犯罪者の行動に適応しリアルタイムで自動更新されるので、被害を受ける前に攻撃を防げる可能性が高まります。
三つ目の理由は、誤検知を避けられることです。不正利用を行うサイバー犯罪者も通常の顧客も人間の目でふるまいを見分けることは困難です。しかし、機械学習であれば、人間が意識しない些細な違いも把握できるので、正しく犯罪者と善良なユーザを識別できることが期待できます。
機械学習とルールの比較
不正利用検知で従来用いられていたのは手動で更新されるルールベースシステムです。ルールベースシステムでは、if-then文などで記述されたルールを1つずつ確認し、マッチするルールがあった場合に、明示的に定められたアクションを取ります。新しいルールに対応するためにはルールの追加や更新が必要で、コストと時間がかかります。
一方、機械学習は決定論ではなく確率論であり、データを元に統計モデルを用いて将来の結果を予測します。電子メールのスパムフィルタが、受信箱に配信するメッセージを認識してスパムを学習するのと同様に、機械学習を用いた不正利用検知システムは、不正な購入の特徴を学習し、正当なものと区別できます。明示的にプログラムされていなくても、学習、予測、判断を行うことができるのです。
機械学習による不正利用検知システムは、不正な取引の自動化された審査システムの一部として導入されることが多くなっています。リスクの高い取引、アカウント、リスクの高いログインを識別し、支払い詐欺、アカウントの不正利用、コンテンツの不正利用、アカウントの乗っ取りを防げるようになります。機械学習により、ルールベースシステムの最も複雑なルールセットよりも、より高い精度による不正利用検知と誤検知の防止を両立できます。その結果、自動化によるコスト削減が期待できます。
<機械学習とルールベースの長所と短所>
機械学習システムの開発には、いくつかの段階があります。
- データの収集と前処理(正規化・特徴抽出)
- データモデルの構築と展開
- データモデルの評価とモニタリング
- 1~3を適切な予測結果が得られるまで繰り返す
マクニカネットワークスが提供する不正利用検知システム「Sift」を例に、順を追ってみていきましょう。
機械学習の前段階-データの収集と前処理
不正利用検知を成功させるためには、大量の高品質なデータにアクセスする必要があります。利用するデータの質は、結果の質に直結します。
以下に、一例としてSiftが利用しているデータのごく一部を紹介します。SiftはこれらのデータをSDK、JavaScript、APIを介して収集します。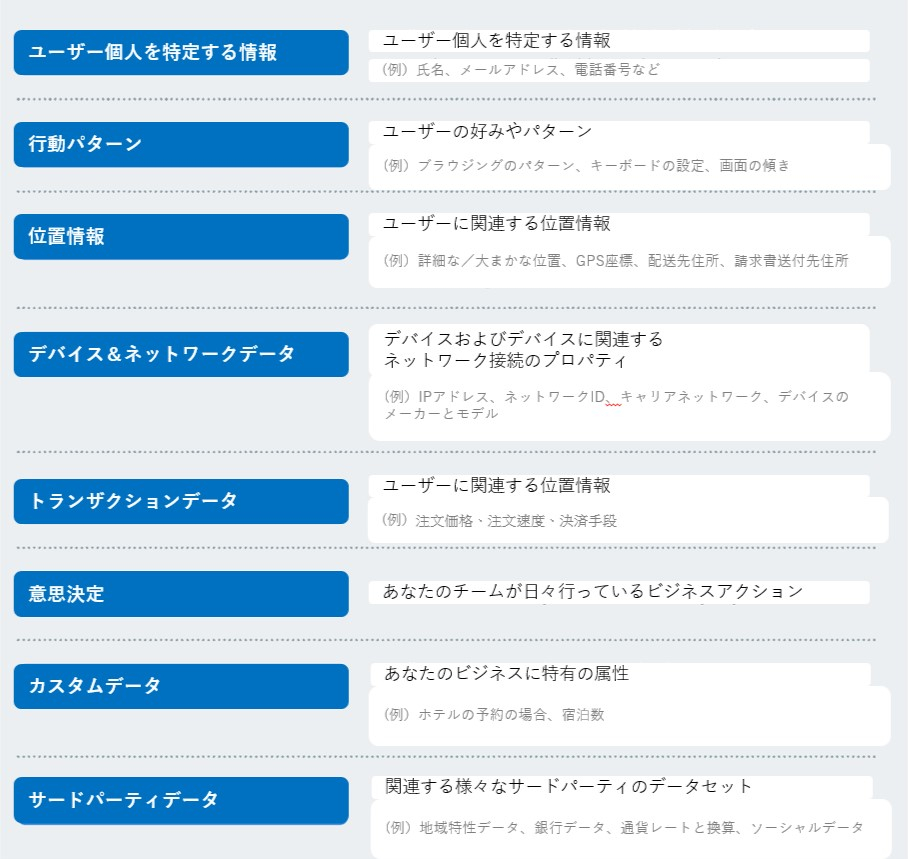
取得したデータを学習データにするために、「正規化」と「特徴抽出」を行います。
「正規化」は、得られた生データの記載を統一し、同じものは同じであると機械学習アルゴリズムに分かるように整理することです。例えば住所であれば「3丁目2番地1号」、「3丁目2-1」、「3-2-1」など複数の記載方法が考えられますが、これを全て同じであるとして学習させる必要があります。
「特徴抽出」は、正規化されたデータを、不正利用検知のための機械学習モデルに入力するための構造化です。Siftは、長年の不正利用検知への取り組みを通して10,000以上の特徴を持つライブラリを構築し、不正利用のパターンを発見するために使用しています。データライブラリはSiftを利用する企業からのフィードバックにより日々更新され、不正利用検知の精度を高めるために役立っています。
データモデル構築
Siftの機械学習モデルは、さまざまなタイプの不正利用に対して、複数の予測モデルを組み合わせて構成されています。データモデルの中には、Siftの顧客に共通する不正利用のパターンを学習したもの、業界特有のもの、特定の組織に合わせて調整されたものなどがあります。このようなモデルの組み合わせにより、ログインや取引の一つ一つを正確にスコアリングすることができます。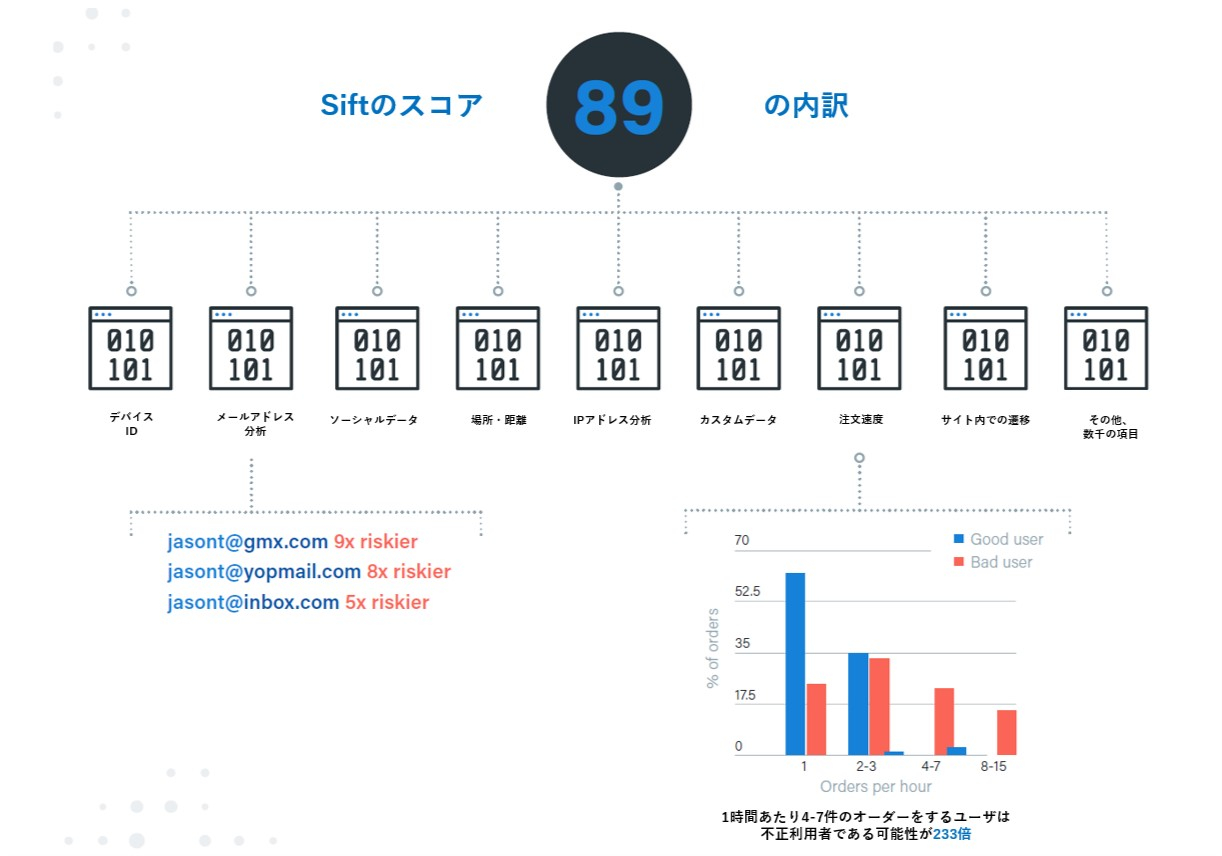 Siftでは、限られた情報しか得られない時にも使えるロジスティック回帰、因果関係が解釈しやすいランダムフォレスト、自然言語処理に用いられるN-gram解析、得られた結果から原因を確率的に推測できる単純ベイズなどのアルゴリズムを併用しています。中でも最も重視しているアルゴリズムが深層学習(ディープラーニング)です。
Siftでは、限られた情報しか得られない時にも使えるロジスティック回帰、因果関係が解釈しやすいランダムフォレスト、自然言語処理に用いられるN-gram解析、得られた結果から原因を確率的に推測できる単純ベイズなどのアルゴリズムを併用しています。中でも最も重視しているアルゴリズムが深層学習(ディープラーニング)です。
Siftにおける深層学習の活用
深層学習は、多くの学習データから、人間の脳のようにパターンを発見し、独立して学習することができます。これらのアルゴリズムは、多層構造の回帰型ニューラルネットワーク(RNN)をベースに構築されています。
たとえ人の目で不正利用が簡単に判別できたとしても、その不正利用を簡単に検出するメカニズムを手動で実装することはきわめて困難です。例えば、同じアカウントに対して、注文と新しいクレジットカードの追加を短時間に交互に繰り返すユーザがいたとします。人間であれば直感的に怪しいと感じますが、不正利用であると検出するためのメカニズムを手動で設定する場合は、「時間あたりの取引回数」のような指標に対して閾値を設定する必要があります。すると、閾値をわずかに下回る不正ユーザを見逃したり、逆に正当なユーザを不正と判定してしまうリスクが発生することになります。
Siftは、システム内のユーザの行動を時系列で学習するために深層学習を使用しています。ユーザの行動の時系列の情報を元に自動的に特徴を抽出し、どのような行動の連続が通常の行動や不正利用者の行動と関連性が高いかを予測するモデルを作成します
深層学習導入のメリットの一つは、特徴抽出を人間が行う必要がなくなることです。これにより、時間とリソースを大幅に節約できます。深層学習の時系列分析と他のモデルとの組み合わせにより、不正利用検知の精度が大幅に向上します。Siftによれば、深層学習の導入により、不正利用検知の精度が10%向上したとのことです。
行動バイオメトリクスデータからの学習に大きな可能性
深層学習は、タイピング、マウス操作、モバイルデバイスの持ち方など、ユーザの行動バイオメトリクスデータ(個人を特徴づける行動)の不正利用防止への活用の基盤となります。行動バイオメトリクスデータは非常に複雑であり、従来の機械学習モデルに投入するための適切な特徴を抽出することは非常に困難です。しかし、深層学習モデルは、複雑なデータから特徴を自動的に抽出することに適しています。これにより、今まで活用ができなかったさまざまなデータの中からも、価値あるパターンを見落とさず特定できると考えられます。
まとめ
機械学習の中でもとりわけ深層学習は、人間によるプログラミングを必要としないにもかかわらず、精度の高い予測ができるという特徴があります。一方で、機械学習の実装には、大規模なデータセットを高速に処理できるインフラだけでなく、データを抽出、変換するシステムや、解析アルゴリズムの実装が必要です。これらを自社で構築・運用することは非常に困難であると考えられます。
Siftは、既に深層学習を導入しており、素晴らしい成果を出しています。JavaScriptやSDKを使ってデスクトップとモバイルのデータをまとめて扱ったり、REST APIを使ってサイトのバックエンドシステムを接続したりすることができます。Siftの機械学習を活用した高精度な不正利用防止は、進化するサイバー犯罪者に立ち向かう強力な道具となることが期待できます。
▼不正利用防止ソリューションの事例はこちら


▼オンデマンド動画はこちら


- ▼セミナー案内・ブログ更新情報 配信登録
